
آموزش خوداصلاحی به LLMها: کلید ساختن هوش مصنوعی ارزانتر و کارآمدتر.
با روش «بازتاب، تلاش، پاداش» آشنا شوید
مقدمه
مدلهای زبان بزرگ (LLM) مانند ChatGPT و امثال آن، دنیای ما را متحول کردهاند. آنها میتوانند شعر بگویند، کد بنویسند و مقالات پیچیده را خلاصه کنند. اما یک حقیقت انکارناپذیر وجود دارد: این مدلها هنوز هم اشتباه میکنند.
گاهی اوقات اشتباهاتشان جزئی و قابل چشمپوشی است، اما گاهی میتواند منجر به نتایج کاملاً غلط و غیرقابل اعتماد شود. مشکل بزرگتر این است که «آموزش دادن» به این غولهای دیجیتال برای جبران یک اشتباه، فرآیندی بسیار پرهزینه و پیچیده است. اما اگر راهی وجود داشت که هوش مصنوعی خودش یاد بگیرد چگونه از خطاهایش درس بگیرد؟
یک پژوهش جدید و هیجانانگیز با عنوان "Reflect, Retry, Reward" (بازتاب، تلاش مجدد، پاداش) دقیقاً به همین موضوع پرداخته است. محققان، چارچوبی هوشمندانه را معرفی میکنند که به مدلهای هوش مصنوعی میآموزد نه تنها اشتباه خود را تشخیص دهند، بلکه روی آن «تأمل» کرده و در تلاش بعدی، عملکرد بهتری از خود نشان دهند. این روش، دریچهای نو به سوی ساختن مدلهایی باز میکند که قابلاعتمادتر، کارآمدتر و به طرز شگفتانگیزی «خودآگاهتر» هستند.
چرا اصلاح هوش مصنوعی دشوار است؟
وقتی یک مدل زبانی بزرگ در انجام یک وظیفه شکست میخورد، اولین راهحلی که به ذهن میرسد، آموزش مجدد یا بهینهسازی (Fine-tuning) آن با دادههای جدید و صحیح است. اما این کار چند چالش اساسی دارد:
- نبود دادههای آموزشی: برای بسیاری از کارهای خاص، ممکن است مجموعه دادهای از «پاسخهای صحیح» وجود نداشته باشد.
- هزینه و زمان: آموزش مجدد این مدلهای عظیم، نیازمند قدرت محاسباتی بسیار بالا و صرف زمان طولانی است.
- ناتوانی در تولید داده مصنوعی: اگر حتی بهترین مدلهای موجود نیز در حل یک مسئله مشکل دارند، نمیتوان از آنها برای تولید دادههای آموزشی مصنوعی و قابل اعتماد استفاده کرد. روشهای جایگزین مانند «زنجیره افکار» (Chain-of-Thought) که مدل را وادار به توضیح مراحل استدلالش میکند، تا حدی مؤثر بودهاند. اما اثربخشی آنها به شدت به نوع دستوری که به مدل داده میشود بستگی دارد و یک راهحل دائمی نیست. اینجاست که چارچوب «بازتاب، تلاش مجدد، پاداش» وارد میدان میشود.
معرفی چارچوب جادویی: بازتاب، تلاش مجدد، پاداش
این روش، یک فرآیند سه مرحلهای ساده اما بسیار قدرتمند را دنبال میکند که هدف آن، آموزش مهارت «خودبازبینی» (Self-Reflection) به مدل است.
- تلاش اول (و شکست): مدل برای اولین بار سعی میکند یک وظیفه را انجام دهد. یک سیستم ارزیاب خودکار (Validator) بررسی میکند که آیا پاسخ صحیح است یا خیر. اگر پاسخ درست بود، کار تمام است. اما اگر شکست خورد، وارد مرحله دوم میشویم.
- بازتاب (Reflection): به مدل گفته میشود: «شما در تلاش قبلی شکست خوردید. لطفاً روی دلایل اشتباه خود تأمل کنید و توضیح کوتاهی بنویسید که به شما کمک کند در تلاش بعدی بهتر عمل کنید.» مدل در این مرحله یک متن «خودبازبینی» تولید میکند.
- تلاش مجدد و پاداش (Retry & Reward): مدل یک بار دیگر همان وظیفه را امتحان میکند، اما این بار متن خودبازبینی که خودش تولید کرده را نیز به عنوان راهنما در اختیار دارد. اگر در این تلاش دوم موفق شود، یک اتفاق کلیدی رخ میدهد: مدل نه برای پاسخ صحیح، بلکه برای تولید آن متن خودبازبینی مؤثر پاداش میگیرد.
نکته طلایی دقیقاً همینجاست. این سیستم به مدل یاد نمیدهد که صرفاً پاسخ یک مسئله خاص را پیدا کند؛ بلکه به او میآموزد که چگونه «بازتابهای ذهنی» بهتری تولید کند تا به طور کلی در حل مسائل موفقتر عمل نماید.
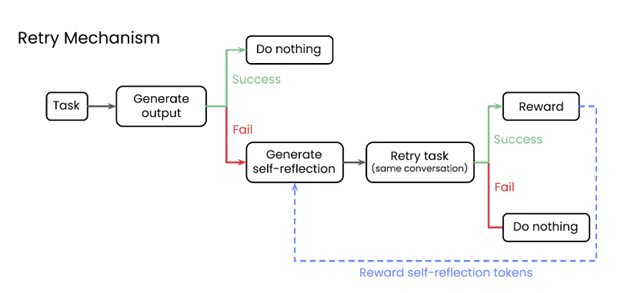
شکل ۱: سازوکار «بازتاب، تلاش مجدد، پاداش» پس از شکست در تلاش اول، مدل وادار به تولید یک «خودبازبینی» درباره دلیل خطا میشود. سپس با استفاده از این راهنمایی، مجدداً تلاش میکند و در صورت موفقیت، به خاطر تولید آن بازبینیِ کارآمد پاداش میگیرد.
این سیستم چگونه کار میکند؟
قلب تپنده این مکانیزم، نوعی از یادگیری تقویتی (Reinforcement Learning) است. یادگیری تقویتی را میتوان مانند آموزش دادن به یک حیوان خانگی در نظر گرفت. وقتی سگ شما کار درستی انجام میدهد، به او تشویقی میدهید (پاداش) تا آن رفتار را تکرار کند.
در این پژوهش، محققان از یک الگوریتم یادگیری تقویتی پیشرفته به نام GRPO استفاده میکنند. این الگوریتم برای پاداش دادن به توکنها (کلمات) استفاده شده در متن «خودبازبینی» به کار میرود. هرگاه یک خودبازبینی منجر به موفقیت در تلاش دوم شود، سیستم آن کلمات و ساختارها را به عنوان یک استراتژی موفق علامتگذاری میکند و مدل را تشویق میکند تا در آینده بازتابهای مشابهی تولید کند. این رویکرد باعث میشود مدل به جای حفظ کردن پاسخها، مهارت کلی «استدلال و تحلیل خطا» را بیاموزد.
نتایج شگفتانگیز: وقتی مدلهای کوچک از غولها پیشی میگیرند
اثربخشی این روش در دو حوزه آزمایش شد: فراخوانی تابع (Function Calling) که یک وظیفه فنی در کدنویسی است و حل معادلات ریاضی (Countdown Math Equations). نتایج خیرهکننده بودند:
- در حل معادلات ریاضی، عملکرد مدلها پس از آموزش تا ۳۴.۷٪ بهبود یافت.
- در وظیفه فراخوانی تابع، شاهد بهبود ۱۸.۱٪ در دقت بودیم.
اما شگفتانگیزترین نتیجه این بود: یک مدل Qwen-2-7B (با ۷ میلیارد پارامتر) که با این روش آموزش دیده بود، توانست از یک مدل آموزش ندیده Qwen-2-72B (با ۷۲ میلیارد پارامتر) که ۱۰ برابر بزرگتر بود، عملکرد بهتری داشته باشد! این یعنی با آموزش مهارت خودبازبینی، میتوان مدلهای کوچکتر و بهینهتر را به سطحی از توانایی رساند که پیش از این تنها از غولهای سختافزاری انتظار میرفت.
تکامل خودبازبینی: از متون طولانی و گیجکننده تا راهنماییهای دقیق
یکی دیگر از مشاهدات جالب این پژوهش، تغییر کیفیت متون خودبازبینی قبل و بعد از آموزش بود. در ابتدا، وقتی از مدل خواسته میشد روی اشتباهش تأمل کند، متون طولانی، تکراری و گاهی بیربط تولید میکرد. اما پس از آموزش با روش «پاداش»، این بازتابها به طرز چشمگیری کوتاهتر، دقیقتر و کاربردیتر شدند. مدل یاد گرفته بود که به جای پرحرفی، مستقیماً به نکته کلیدی که باعث خطایش شده بود اشاره کند.

شکل ۲: بازتابهای بهتر آموزش مدلها با روش یادگیری تقویتی GRPO، کیفیت خودبازبینی آنها را متحول میکند؛ به طوری که بازتابهای طولانی و گیجکننده، جای خود را به راهنماییهای دقیق، کوتاه و شفاف میدهند.
آیا مدل مهارتهای قبلی خود را فراموش میکند؟
یک نگرانی رایج در هنگام بهینهسازی مدلهای هوش مصنوعی، پدیدهای به نام فراموشی فاجعهبار (Catastrophic Forgetting) است. در این پدیده، مدل حین یادگیری یک مهارت جدید، مهارتهای قبلی خود را از دست میدهد. برای مثال، ممکن است در حل مسائل ریاضی بهتر شود اما توانایی درک مطلب عمومی آن افت کند.
خوشبختانه، محققان این موضوع را نیز بررسی کردند. آنها دریافتند که چون این روش یک مهارت عمومی (خودبازبینی) را آموزش میدهد و نه یک وظیفه خاص، عملکرد مدلها در بنچمارکهای استاندارد دیگر تقریباً بدون تغییر باقی میماند. در اکثر موارد، افت عملکرد کمتر از ۱٪ بود و در برخی موارد حتی شاهد بهبود جزئی نیز بودیم. این نشان میدهد که روش «بازتاب، تلاش مجدد، پاداش» یک رویکرد ایمن و پایدار برای بهبود مدلهاست.
نتیجهگیری: آیندهای روشنتر برای هوش مصنوعی قابل اعتماد
این مقاله چیزی فراتر از یک بهبود فنی ساده را به نمایش میگذارد. این پژوهش یک تغییر پارادایم در نحوه نگرش ما به «یادگیری» در ماشینهاست. به جای اینکه ما به طور مداوم به هوش مصنوعی بگوییم چه کاری انجام دهد، میتوانیم ابزارهایی را در اختیارش بگذاریم تا خودش یاد بگیرد چگونه بهتر شود.
این روش به ما اجازه میدهد:
- مدلهای هوش مصنوعی قابل اعتمادتری بسازیم که میتوانند خطاهای خود را اصلاح کنند.
- با استفاده از مدلهای کوچکتر و بهینهتر، به نتایجی در سطح مدلهای غولپیکر دست یابیم.
- فرآیند بهبود هوش مصنوعی را بدون نیاز به مجموعه دادههای عظیم و هزینههای سرسامآور محاسباتی، تسریع کنیم.
در جهانی که وابستگی ما به سیستمهای هوشمند روزبهروز بیشتر میشود، توانایی یک ماشین برای «تأمل» در اشتباهاتش و «یادگیری» از آنها، دیگر یک ویژگی لوکس نیست، بلکه یک ضرورت است. این چارچوب، گامی بزرگ در مسیر تحقق این آینده هیجانانگیز است.
